I wrote the roots of this article in reply to a friend’s request for me to explain the advantages of ZFS over NTFS. However, a direct comparison is difficult, because ZFS is different from a standard filesystem in a number of fundamental ways. I must provide a history/primer on how data is stored on hard drives – though for simplicity’s sake, I will intentionally leave out a lot of details, features, exceptions, and edge cases (so don’t @ me). Hopefully I will be straightforward enough that, if you’ve ever partitioned a hard drive and installed an operating system (or created one), you can understand.
Please note, I am not an expert on ZFS. I’m just a satisfied customer (figure of speech – it’s free) who uses it both personally and professionally.
The modern Windows “storage stack” (a term I just now made up), as found on most individual PCs, is as follows:
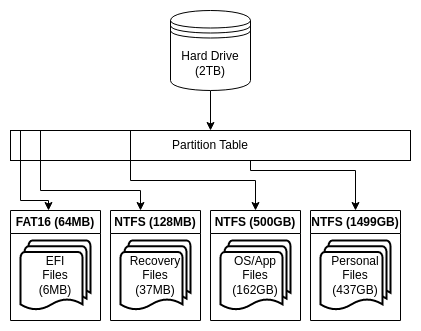
Not the actual Microsoft partition scheme, but hopefully you get the concept
Physical hard drive > partition table > filesystem(s) (Mostly NTFS)
This “storage stack” is decades old. Each layer expects that itself, and the layers it depends on, will be immutable. If you want to make changes, such as changing to a new hard drive or restructuring/resizing partitions, it typically requires downtime and a potentially dangerous series of steps. Further, there is no data redundancy. If the physical hard drive fails – wholly or partially – where data is contained, you will lose data. This single point of catastrophic failure is one reason why it is so important to keep regular backups of PCs, and/or to save your important data to a storage solution with redundancy.
If you want data redundancy in Windows, and perhaps uptime while changing hard drives, then you can use RAID, which stores two or more copies of your data across two or more hard drives running concurrently. Because NTFS is designed to be installed on a single contiguous partition, it is necessary to use a solution that tricks NTFS into thinking that’s where it is. Thus, proprietary hardware and firmware RAID systems have been the typical option in a Windows environment. This changes the “storage stack” to:
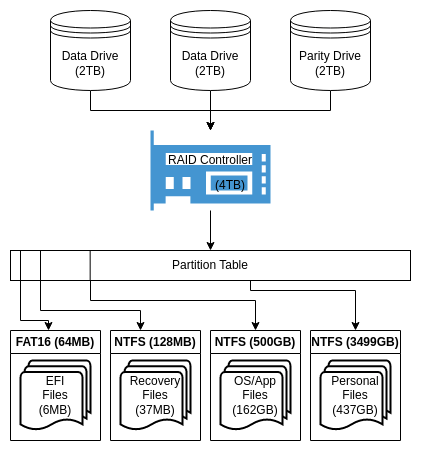
A minimal RAID 5 array is shown for demonstration purposes. Three 2TB drives provide 4TB of usable storage space, with 2TB reserved for parity.
Multiple physical hard drives > RAID controller (proprietary) > partition table > filesystem(s) (NTFS)
This is how physical Windows servers are typically set up.
A very basic Linux “storage stack” is set up nearly identically to that of Windows. However, we have more options concerning redundancy and volume management. Linux supports a form of software RAID called “mdraid,” which more or less does what a hardware/firmware RAID controller does, but without dependence on proprietary solutions. Furthermore, Linux supports a form of Logical Volume Management, creatively called “lvm,” which sits between the partition table and filesystem, and it allows transparent manipulation of data. With LVM, we can create, delete, and resize virtual partitions much more easily, with minimal or no downtime, often online. A common physical Linux “storage stack” looks like:
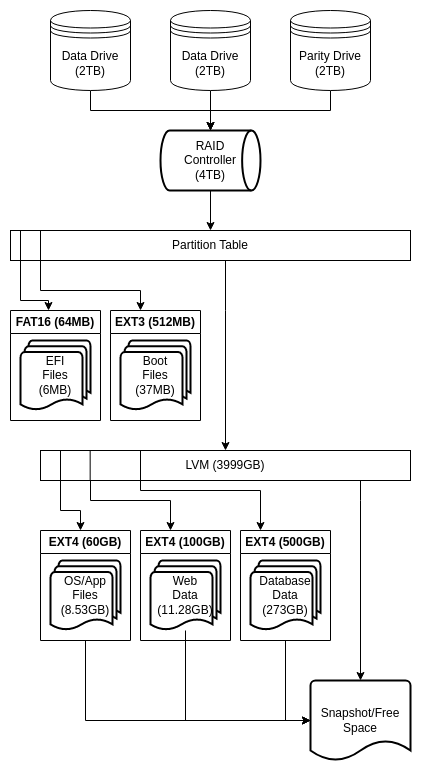
This is getting convoluted
Multiple physical hard drives > RAID controller (mdadm) > partition table > LVM > filesystem(s) (Typically Ext4)
Some enterprise NAS solutions are configured this way.
LVM also has another advantage, in fact, often the primary reason it is used: snapshots. Snapshots allow a computer to save a copy of the filesystem’s state at a given point in time, allowing it to be rolled back. This mitigates data loss and operational issues such as those resulting from corruption, viruses, accidental file deletion, or bad updates.
The problem remains, however, that the layers of the “storage stack” do not communicate.
- Both Linux and Windows RAID solutions can compensate for certain disk failures, but neither typically correct for “bit rot,” which is when a bit flips from a 1 to 0 or vice-versa without generating any explicit errors. The RAID layer does not know what the bit is supposed to be. It only knows that it was able to read the bit from the drive without issue, and typically does not compare the result with parity; you may never know that your data has been corrupted at all.

An example of bit rot in a jpeg file, photo by Jim Salter
- Further, if there is any detectable error, the filesystem and RAID layer do not work together to identify the affected files. Upon such a detectable error, the RAID controller will often simply mark the entire drive as bad. If any errors crop up in reading the “good” drive while replacing the bad one, you may then lose all of your data.
- Replacing disks takes the maximum amount of time; since the RAID layer is unaware of the filesystem layer, it must dumbly copy the whole disk, even the parts that the filesystem has not actually allocated to a file.
- LVM must trick the filesystem into thinking it is on an inflexible legacy partition. This means that the administrator must make careful plans about how much space the filesystems and snapshots are allocated. It is common to allocate too much space to a filesystem and run out of physical drive for other purposes, or allocate too little and have to expand it later. Which LVM makes relatively convenient, but it’s still something to worry about.
- LVM snapshots are space-hungry and prone to failure. Microsoft’s VSS has problems of its own.

What is special about ZFS is that it combines the functions of the RAID controller, volume manager, and filesystem into a unified whole. So, with ZFS, our “storage stack” looks like:
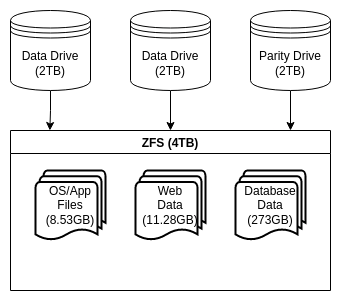
Each dataset only takes as much space as it needs, and no space needs to be reserved for snapshots
One or more physical hard drives > ZFS
Now, we have all the advantages of RAID and LVM, but all the layers also work together and so their functionality is enhanced.
- ZFS checksums all data, so that if a bad bit is pulled from a drive, it knows immediately that something is wrong, and can correct for it on-the-fly. If there is an unrecoverable error, it can narrow down the affected file.
- Replacing hard drives is now much less risky, because ZFS does not drop the entire “bad” drive before replacement; it will continue to use the good areas of the disk for redundancy, until the new drive is in place. If any unrecoverable errors are encountered, only the affected files will be lost.
- Replacing hard drives is faster. Since the RAID layer is aware of the files, it only needs to copy and calculate parity for the files, and not the unallocated space.
- There is no longer a need to statically assign volume sizes; data is organized into “datasets” to which space is dynamically allocated from the “pool” as files are written. This can greatly enhance efficiency of storage utilization.
- These datasets can be assigned properties such as block size, encryption, compression, and more, which would have required dedicated volumes and sometimes extra layers of software for each, in older storage stacks.
- Datasets can be individually snapshotted and restored. Snapshots are seamless, instant, reliable, low-overhead, and only take up as much space as needed to reflect differences from the source. This makes it practical to keep sub-hourly snapshots.
- External backups can be updated incrementally through this dataset/snapshot paradigm, with no downtime, even over a network.
ZFS has a few drawbacks, though.
- Because of the overhead of checksumming data (which can technically be disabled, but it is probably not worth the tradeoff), ZFS is slower than other filesystems by nature. It also tends to slow down greatly, and perhaps permanently, when the pool has nearly reached capacity.
- ZFS is inflexible with regards to the topology of a RAID5/6 volume; once made,
it cannot be changedchanges are limited (RAIDz expansion has since been implemented, but disks can only be added and not removed) compared to mdraid. Further, you can only add raidgroups/drives to a pool, and never remove them. - Most computers and operating systems do not support booting from ZFS natively; if you want to use it as an OS root filesystem, you will still need to have EFI and boot partitions somewhere (though, it is possible to install ZFS to a partition rather than directly to a hard drive).
However, the advantages greatly outweigh the disadvantages, especially in an enterprise environment (though, I use it on my home computers as well). It is currently one of, if not the, preferred filesystems for ensuring data integrity.
As of the time of writing this article, the closest competitors to ZFS are Linux’s Btrfs, which is more feature-rich though not as mature, and a promising future contender known as BCacheFS. Read more about this generation of filesystems at Ars Technica.